Lead Scoring Systems: The Practical Playbook for 2026
A lead score doesn't create pipeline. Speed-to-lead on the right people does.
Most lead scoring systems fail because they stop at "points in a field" instead of becoming an operating agreement between marketing, sales, and RevOps.
You'll leave with a fit/engagement template, SLA bands reps actually follow, and a validation workflow you can run in a week.
What you need (quick version)
- Pick the bottleneck you're fixing. In most funnels, the biggest leak is MQL-to-SQL (Digital Bloom's benchmark compilation puts it around 15-21%).
- Don't score too early. Default's analysis of 100 B2B software websites shows that once you're at 25,000+ visitors, visitor-to-demo request conversion often falls under 1%. If you don't have enough signal volume, scoring turns into theater.
- Split the score in two: Fit (who they are) + Engagement (what they did).
- Define 4-6 score bands (not one threshold) and what each band means in plain English.
- Attach routing + SLAs to every band (owner, follow-up window, required outcome).
- Add anti-signal rules: exclusions, negative points, and decay so junk never outranks real buyers.
- Validate with outcomes: conversion-by-band, lift, backtests, and a champion/challenger test.
- Govern changes like releases: versioning, staged rollouts, and reporting annotations to prevent MQL spikes.
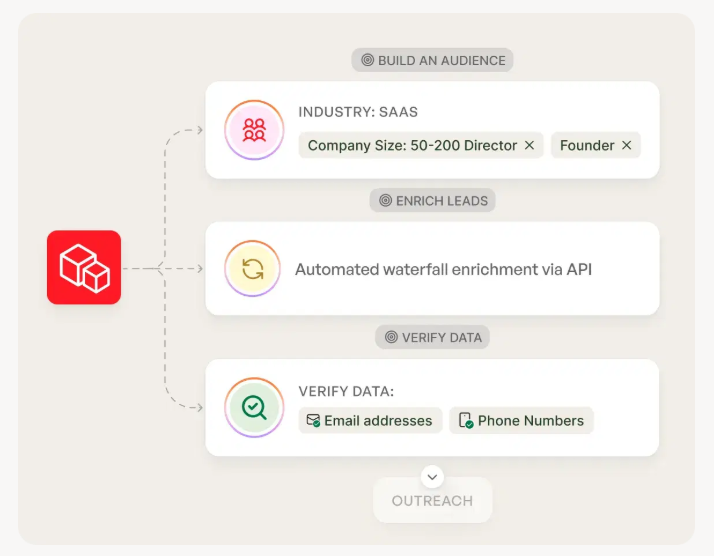
What a lead scoring system is (model + workflow + tools)
A lead scoring model is the math (rules or ML). A lead scoring system is the model plus everything that makes it usable: identity resolution, enrichment, routing, SLAs, reporting, and a feedback loop that keeps the score honest.
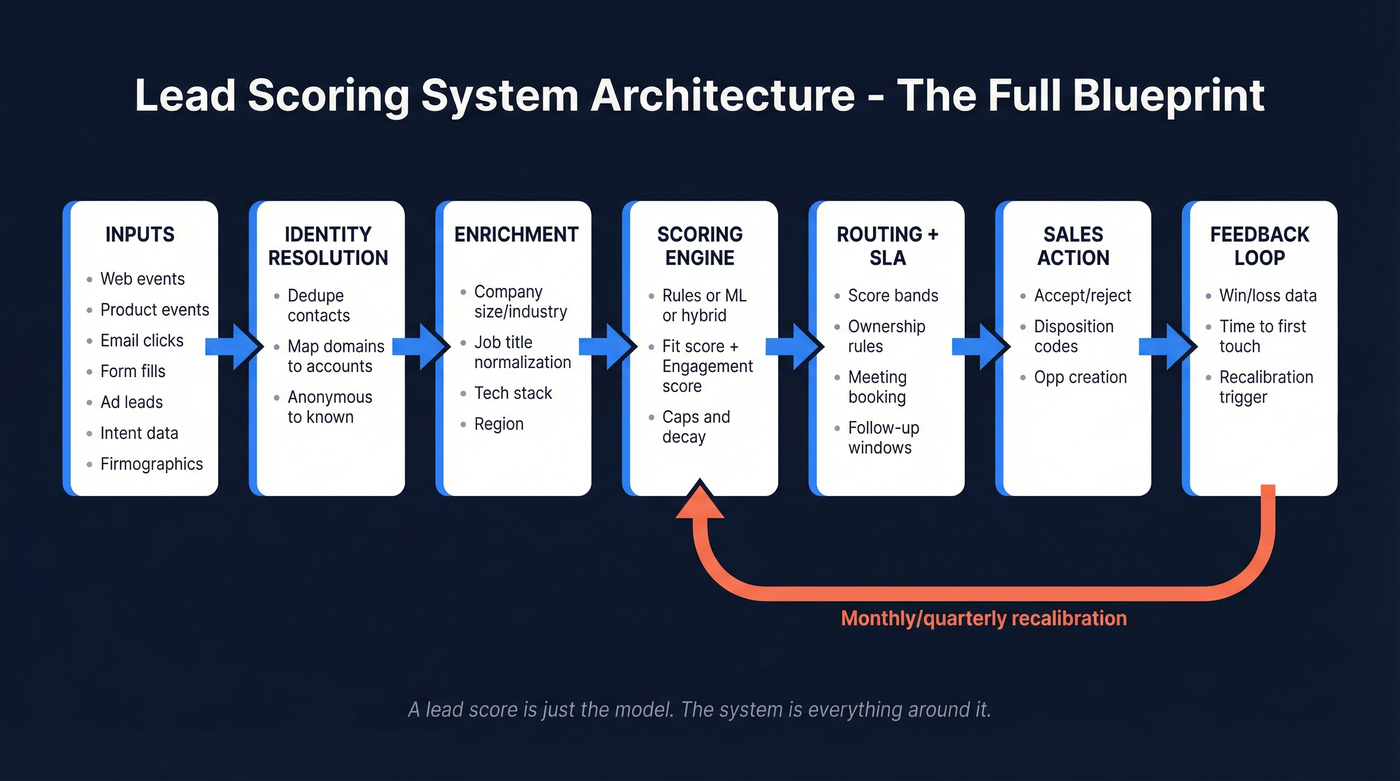
When sales says "the score is wrong," the points usually aren't the real problem. The system is. Reps don't know what a 78 means, routing doesn't change, or the CRM's full of duplicates and stale titles, so the score becomes noise.
Here's the blueprint we use when we audit scoring in a real RevOps environment:
- Inputs: web events, product events, email engagement, form fills, ad lead forms, intent topics, firmographics, role/seniority, technographics
- Identity resolution: dedupe contacts, map domains to accounts, unify anonymous-to-known activity, handle subsidiaries
- Enrichment: fill missing company size/industry/region/tech stack; normalize job titles and seniority
- Scoring engine: rules-based, predictive, or hybrid; fit + engagement split; caps and decay
- Routing + SLA: score bands, ownership rules, round-robin, meeting booking, alerts, follow-up windows
- Feedback loop: accepted/rejected reasons, disposition codes, opportunity creation, win/loss, time-to-first-touch
- Retraining cadence: monthly/quarterly recalibration for rules; quarterly/biannual retraining for predictive (or continuous if you're mature)
Mini-template: the "minimum viable architecture" (so your score survives contact chaos)
If you want lead scoring systems to work past week two, you need a small, explicit schema. This is the one we recommend because it's boring, and boring survives.
Core objects
- Lead/Contact (person-level scoring)
- Account (for rollups and account scoring later)
- Activity/Event (web/product/email/ad events)
- Opportunity (the outcome you're optimizing for)
Fields you should standardize (non-negotiable)
lead_source(controlled picklist, not free text)lifecycle_stage+lifecycle_stage_entered_date(timestamps matter for reporting)fit_score,engagement_score,total_score(or keep total optional)score_band(A1/A2... or 0-29/30-59...)score_version(v1/v2/v3)last_activity_at(single "truth" timestamp)routing_owner,routed_at,first_touch_at(to measure SLA compliance)disposition_reason(accepted, rejected, bad fit, no response, student, competitor, etc.)
Event schema (simple but powerful)
event_type(pricing_view, demo_request, webinar_attend, product_signup, etc.)event_timeevent_value(optional: plan, asset name, intent topic)identity_key(cookie/user id to contact id mapping)
Hot take: if you can't reliably answer "what happened first, routing or first touch?" your scoring project's premature. Fix tracking and lifecycle timestamps before you argue about point weights.
When lead scoring is worth it (and when it's a distraction)
| Use lead scoring if... | Skip lead scoring if... |
|---|---|
| You have enough inbound volume to prioritize (Default's dataset shows many B2B sites need serious traffic before intent signals stack up). | You're getting a handful of leads a week. Prioritization isn't the problem, volume is. |
| Sales is missing fast follow-up because everything looks the same in the CRM. | Your ICP isn't clear. Scoring can't fix "we sell to everyone." |
| Marketing + sales will commit to definitions and SLAs. | Sales won't follow SLAs. Pause scoring and fix process/capacity first. |
| You can track outcomes (SQL, opp, win) back to lead attributes and behaviors. | Your tracking's broken (UTMs, source, attribution, duplicates). |
| Someone owns scoring as an ongoing program. | You want "set it and forget it." That's how scoring dies. |
Here's the thing: the most common "implemented too early" pattern is a team with low lead volume building an elaborate scoring model to feel in control. Then they spend weeks debating whether a webinar attendee is +7 or +9 points while the real fix is improving conversion paths, cleaning up routing, and capturing better intent signals.
I've watched this happen in a Monday meeting: the team argued about point weights for 40 minutes, and meanwhile three demo requests sat untouched in the CRM because nobody owned the inbox. That wasn't a scoring problem. That was an operating problem.
Lead scoring fails when enrichment is stale. Prospeo refreshes 300M+ profiles every 7 days - not the 6-week industry average - so your fit scores reflect reality, not last quarter's org chart. 98% email accuracy means your routing SLAs actually connect reps to real buyers.
Stop scoring leads against outdated data. Start with a clean foundation.
The simplest lead scoring systems that actually work (fit + engagement)
The cleanest starting point is the classic split: Engagement score + Fit score.
Keep them separate.
A single blended score hides why someone's "hot," and that's exactly how you lose sales trust.
A practical starter model (rules-based)
| Category | Rule | Points |
|---|---|---|
| High intent | Demo request | +25 |
| High intent | Pricing page view (2+ in 7 days) | +10 |
| Content intent | High-intent asset download | +10 |
| Clicked nurture email | +5 | |
| Fit | ICP industry match | +5 |
| Fit | Target employee range | +5 |
| Fit | Decision-maker title | +15 |
| Negative | Unsubscribe | -15 |
| Negative | Inactivity (no activity 30 days) | -15 |
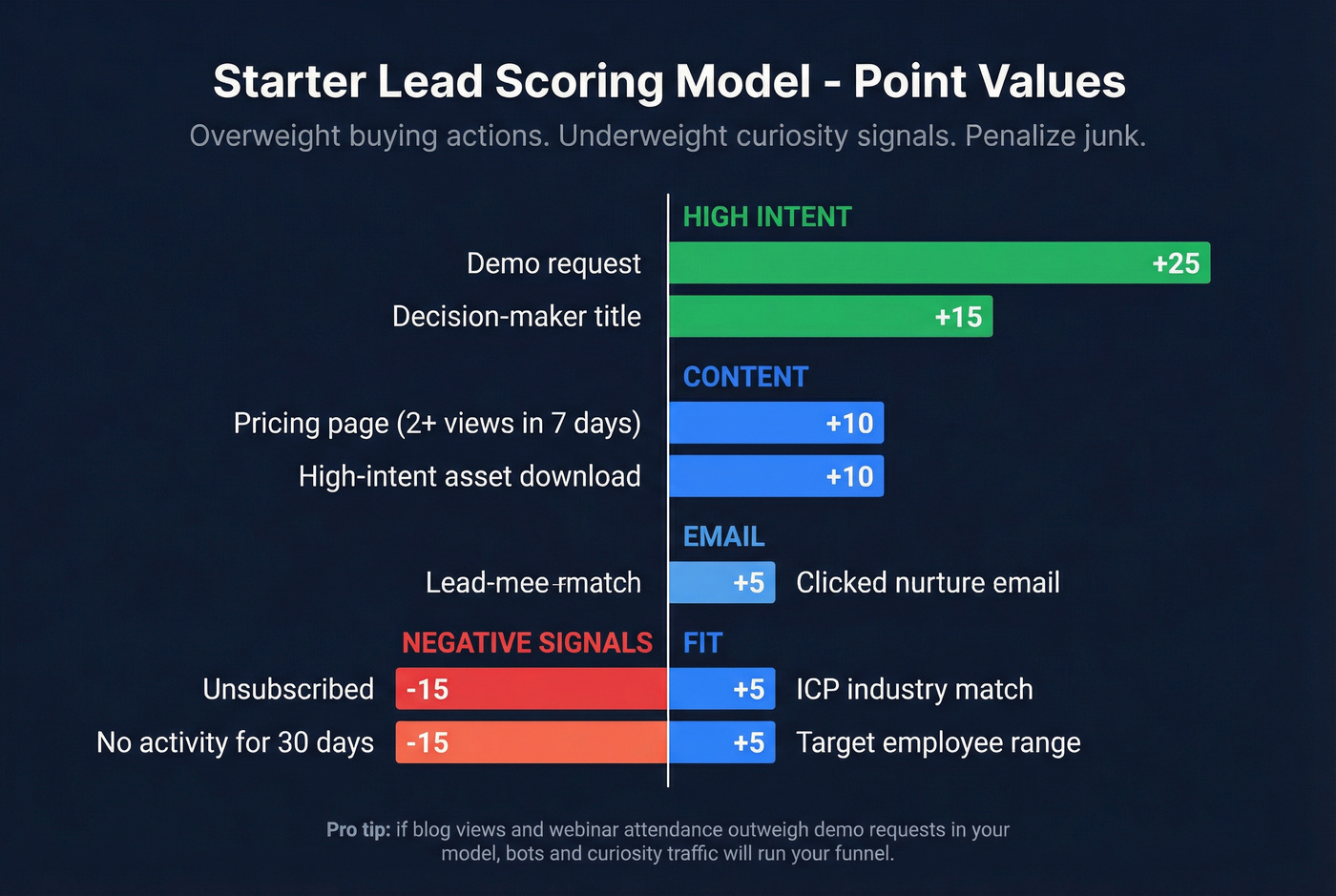
My opinion: overweight explicit buying actions (demo + pricing) and underweight "easy" signals (blog views, generic pageviews). If you don't do this, bots and curiosity traffic will run your funnel.
Worked example: 10 leads, one morning, no ambiguity
Instead of staring at a score field, run a quick "morning sort" test. Here's what routing looks like when fit and engagement are separate:
Leads 1-3: High fit + high engagement
- VP Ops at ICP company, demo request + pricing views -> route to SDR/AE now
- Director IT at ICP company, pricing views + product signup -> route now
- Head of Finance at ICP company, demo request -> route now
Leads 4-6: High fit + low engagement
- VP at ICP company, one webinar attend -> nurture + light outbound
- Manager at ICP company, one high-intent download -> nurture + SDR touch if capacity
- Senior IC at ICP company, newsletter click -> nurture
Leads 7-8: Low fit + high engagement
- Student email, multiple pageviews -> exclude/negative score
- Consultant at tiny agency, pricing views -> qualify carefully; don't burn AE time
Leads 9-10: Low fit + low engagement
- Random Gmail, one blog view -> suppress
- Competitor domain -> exclude
If your system can't produce this kind of obvious sorting, it's not a system. It's a spreadsheet with opinions.
What's a normal MQL threshold?
Most B2B teams land around 60-100 points for an MQL threshold once they've got a few weeks of data. Start at 70, run it for two weeks, then adjust using acceptance rate and conversion-by-band.
Don't "perfect" the number in a meeting.
Fit vs engagement: the two-axis view
Stop thinking in one dimension. Use a 2x2:

- High fit + high engagement: sales now
- High fit + low engagement: nurture + targeted outbound
- Low fit + high engagement: qualify carefully (often false positives)
- Low fit + low engagement: suppress
This is the fastest way to make reps trust scoring, because it answers the only question they care about: "Is this a real buyer, or just noisy activity?"
Score bands, routing, and SLAs (make sales trust the number)
Treat scoring as a contract. Not a dashboard widget.
A contract.
That contract has three parts:
- Definitions: what counts as MQL, SQL, and "sales accepted"
- Routing: who gets what, when, and how
- SLAs: how fast sales follows up by band, and what happens if they don't
Definitions that prevent endless arguing
Pick definitions that are measurable and tied to actions:
- MQL: "Meets fit threshold + engagement threshold and is routed to sales."
- Sales Accepted Lead (SAL): "Sales explicitly accepts ownership (status change) within SLA."
- SQL: pick one and stick to it:
- SQL = discovery scheduled (fast feedback, great for high-volume)
- SQL = opportunity created (cleaner pipeline reporting, slower feedback)
If your org fights about what an SQL is, use discovery scheduled for 60 days to stabilize behavior, then graduate to opportunity created once hygiene's consistent.
The fit/interest matrix (A-D + 1-4)
This is the simplest way to make scoring legible:

- Fit grade: A (best) to D (worst)
- Interest level: 1 (highest) to 4 (lowest)
Example interpretation:
- A1: perfect ICP + high intent -> immediate sales outreach
- A3: perfect ICP + low intent -> nurture + light outbound
- C1: weak fit + high intent -> qualify before burning AE time
- D4: suppress
SLA table (example you can copy)
| Band | Definition | Owner | SLA | Outcome required |
|---|---|---|---|---|
| A1 / Score 90+ | Hot + ICP | AE/SDR | 24h | call + email |
| A2 / 75-89 | Strong | SDR | 48h | sequence start |
| B1 / 70-89 | Engaged, ok fit | SDR | 48h | qualify/dispo |
| A3/B2 / 60-74 | Nurture-ready | Marketing | 7d | nurture track |
| <60 | Not ready | Marketing | - | suppress/educate |

Minimum reporting set (if you don't track this, you're guessing)
Track these weekly, by band and by owner:
- Acceptance rate: SAL / routed
- Speed-to-lead: median minutes from
routed_attofirst_touch_at - SQL rate: SQL / routed (14- and 30-day windows)
- Opportunity rate: opps / routed
- Pipeline per routed lead: $ pipeline / routed
- Win rate by band: wins / opps (slower, but it keeps everyone honest)
Two hard rules:
- If sales ignores A1s, your problem isn't scoring. It's capacity, incentives, or trust.
- If you can't measure opportunity creation by band, don't build predictive scoring yet. You'll train a model on garbage outcomes and call it "AI."
Stop false positives: negative scoring, exclusions, and score decay
False positives are why sales stops trusting the number. Once trust's gone, you don't win it back with "better weights." You win it back by removing obvious junk.
And yes, this part's annoying. It's also where scoring projects usually die.
Copyable rule blocks (examples you can implement today)
Pricing/careers + role weighting
- Pricing page view: +5
- Careers page view: -10
- Decision-maker: +25
- Manager: +10
- Individual contributor: +5
Negative intent (job seekers, researchers, competitors)
- Student/education email domains: -25
- Competitor domains: exclude entirely
Behavior that should cool a lead down
- Unsubscribe: -15
- Hard bounce: exclude + flag for cleanup
- No activity in 30 days: -15 (or apply decay)
Exclusions checklist (do this before you touch weights)
- Exclude existing customers (unless you're scoring for expansion)
- Exclude partners/resellers (route separately)
- Exclude job applicants
- Exclude internal traffic and known bots
- Exclude competitor domains and disposable emails
Skip this if you're still routing duplicates to two reps at once. Fix dedupe first, or you'll misread every scoring report you build.
Score decay (the part everyone forgets)
Interest expires. A lead that binge-read your site 60 days ago isn't hot. It's history.
Decay options that work:
- Time-based decay: reduce engagement score by 10-20% every 7-14 days without activity
- Event-based reset: if no activity for 30 days, drop engagement to a floor
- Recency weighting: recent actions count more than old ones
Common failure -> fix:
Failure: "Once an MQL, always an MQL." Fix: decay + a re-qualify rule (for example, must have activity in last 14 days to stay in A1/A2).
Add momentum (urgency beats absolute score)
Absolute score answers "how much intent have we ever seen?" Reps act on "what changed this week?"
Borrow the Marketo Sales Insight idea and add a simple momentum metric:
- Momentum = engagement score change in last 7 days
- Create an urgency flag (0-3) based on momentum:
- 3: +25 or more in 7 days (spike)
- 2: +10 to +24
- 1: +1 to +9
- 0: flat or negative
Then prioritize like this:
- A2 with urgency 3 outranks A1 with urgency 0 for first-touch order.
- SLA timers stay the same, but rep task queues become sane.
This one change fixes the classic complaint: "The score says they're hot, but nothing happened recently."
How to validate lead scoring systems (lift, backtesting, ROC AUC)
If you can't prove your scoring works, it turns into politics. Marketing defends it, sales ignores it, and RevOps becomes the referee.
Validation's straightforward if you keep it outcome-driven, and if you accept one uncomfortable truth: a scoring model that "feels right" but doesn't create lift is just a story you tell yourself to make the funnel feel less chaotic.
Step-by-step validation workflow
Pick your success event. Start with SQL or opportunity created. Closed-won's valuable, but slow and noisy.
Create score bands (not just a threshold). Example: 0-29, 30-59, 60-74, 75-89, 90+.
Measure conversion-by-band. For each band, compute:
- % that became SQL within 14/30 days
- median time-to-SQL
- acceptance rate (sales accepted / routed)
Build a lift chart. Lift = (conversion rate in band) / (overall conversion rate). You want the top bands to show obvious lift, not a flat line.
Backtest before you ship changes. Apply the new rules to the last 60-180 days of leads and see how distributions and conversions would've changed.
Run champion/challenger. Keep the current model (champion) and test a challenger on a subset (region, segment, or random split). Compare lift and downstream pipeline.
If you go predictive, track ROC AUC. ROC AUC tells you how well the model separates converters from non-converters across thresholds. It's the fastest sanity check.
What the ML research says (and why it matters)
A Frontiers in AI case study used real CRM lead data from Jan 2020-Apr 2024 and compared 15 classification algorithms. The best performer was Gradient Boosting, based on accuracy and ROC AUC. Feature importance highlighted source and lead status as influential predictors for conversion. https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1554325/full
Two takeaways that matter in the real world:
- Predictive scoring wins when you've got enough history and consistent outcomes.
- "Boring" fields (source hygiene, lifecycle status discipline) often beat fancy intent signals.
Human oversight (especially for predictive scoring)
If you automate scoring, you still own the consequences. Build a human-in-the-loop process:
- Audit false negatives monthly: sample deals that converted from low-score bands and find the missing signals.
- Allow overrides: reps can flag mis-scored leads with a reason code (and you review patterns).
- Document features used: what inputs the model can and can't use (and why).
- Bias/drift review quarterly: check whether certain segments (region, company size, industry) are systematically under-scored.
- Change control: every scoring change gets a version, a date, and a rollback plan.
This is the difference between "AI scoring" and a system you can defend in a pipeline review.
Data quality is the scoring multiplier (enrichment, verification, freshness)
Stale, unverified data breaks scoring. Full stop.
If titles are wrong, domains are mismatched, and half your emails are dead, your fit score lies and your engagement score gets noisy. Then you tune weights for weeks and wonder why SQL rate doesn't move.
Minimum viable data for scoring:
- Identity: deduped contact, correct company domain, mapped account
- Role: job title normalized, seniority, department
- Firmographics: employee range, industry, region
- Source + lifecycle: consistent source taxonomy, lifecycle stage history
- Reachability: verified email, verified mobile (if you call)
How we operationalize this with Prospeo (data-quality layer)
Prospeo is "The B2B data platform built for accuracy". It's the best choice when email accuracy, data freshness, and self-serve workflows matter more than anything else.
Use it upstream of scoring so you're not scoring ghosts:
- 300M+ professional profiles
- 143M+ verified emails with 98% accuracy
- 125M+ verified mobile numbers with a 30% pickup rate across all regions
- 7-day refresh cycle (industry average: 6 weeks)
- 83% enrichment match rate and 92% API match rate
- Enrichment returns 50+ data points per contact
Two links that matter for RevOps implementation:
- Data enrichment workflows: https://prospeo.io/b2b-data-enrichment
- Enrichment API: https://prospeo.io/data-enrichment-api
Workflow we recommend:
- Verify emails before scoring thresholds matter. Bad emails create fake engagement (bounces, spam flags) and hide real intent.
- Enrich missing fit fields (role, seniority, company size, industry) so fit scoring isn't guessing.
- Refresh weekly before recalibrating weights, because inputs change faster than most teams admit.
If your reps keep saying "these hot leads don't respond," stop tweaking the score and fix reachability. That's where the wins are.
Change management + reporting governance (avoid MQL spikes)
Changing scoring in production can wreck reporting overnight. The classic mess: you publish a new scoring strategy and thousands of existing contacts cross the MQL threshold, dashboards spike, CAC math gets weird, and leadership thinks marketing "tripled MQLs" in a day.
Here's the playbook that prevents that:
- Version everything. Add a
score_versionfield (v1/v2/v3) and stamp it on every scored record. - Annotate dashboards permanently. "Score v2 launched on 2026-XX-XX." Don't rely on tribal memory.
- Stage the rollout. Start with new leads only or one segment (region/BU) for 2-4 weeks.
- Protect lifecycle reporting. Keep a separate "became MQL at" timestamp that only sets once, based on your definition at the time. Don't let score recalculations rewrite history.
- Batch re-enrollment intentionally. If you must re-score old contacts, do it in controlled batches and monitor band distribution.
- Monitor acceptance rate daily for week one. If acceptance drops, roll back fast. Don't argue for a month while pipeline suffers.
One concrete HubSpot gotcha: scoring changes can reclassify contacts in ways that distort "became MQL" reporting unless you explicitly control the timestamping logic. Treat timestamps like accounting: immutable unless you're doing a formal restatement.
Account scoring and MQA (when lead scoring isn't enough)
Lead scoring works when one person can create an opportunity. In many B2B deals, that's not reality. Buying committees show up as scattered signals across multiple contacts, none of whom look "hot" alone.
That's when you add account scoring and an MQA (Marketing Qualified Account) stage alongside MQL.
A simple account scoring approach that works:
- Engagement rollup: take the max engagement score across contacts and count how many contacts are active in the last 14 days.
- Fit rollup: use firmographics/technographics at the account level (industry, size, region, key tech).
- Buying committee signal: add points when you've got 2+ departments engaged (for example, IT + Finance) or 2+ seniorities (manager + exec).
Example MQA rule:
- MQA = Account Fit A/B + (2+ engaged contacts in 14 days OR one contact with urgency 3).
This is how ABM teams stop missing real deals that never trigger a single "perfect" lead score.
Tooling landscape + pricing reality (what "systems" usually run on)
Most lead scoring systems run on a CRM + marketing automation platform, with optional intent and data-quality layers. Tooling matters less than discipline, but pricing and packaging determine what you can actually implement.
Common scoring stacks (and what they cost in practice)
| Layer | Common tools | What you get | Typical market range |
|---|---|---|---|
| CRM | Salesforce, HubSpot | lifecycle + routing | $50-$300/user/mo (plus platform tiers) |
| MAP scoring | HubSpot, Marketo, Eloqua | rules + bands + automation | ~$800-$4,000/mo+ (scales with contacts/modules) |
| B2B automation | Marketing Cloud Account Engagement (Growth+ to Premium+) | scoring + nurture | $1,250-$15,000/org/mo (list pricing) |
| ABM/intent | Demandbase, 6sense | account signals + orchestration | often $30k-$150k/yr |
HubSpot (scoring capabilities + gating)
HubSpot's Lead Scoring tool supports score groups, caps, positive/negative points, and score history/distribution. It's available in Marketing Hub Professional/Enterprise and Sales Hub Professional/Enterprise. For contacts, scoring's in Marketing Hub, and AI engagement/fit scoring is available in Marketing Hub Enterprise. https://knowledge.hubspot.com/scoring/understand-the-lead-scoring-tool
Operational reality: HubSpot legacy score properties stopped updating after Aug 31, 2026. New models need to be recreated in the new Lead Scoring tool.
Pricing reality: teams running real scoring + automation in HubSpot usually land around $800-$3,600+/month once you account for hub tiers, seats, and contact tiers.
Salesforce Marketing Cloud Account Engagement pricing (published list)
Salesforce's B2B automation product is branded as Marketing Cloud Account Engagement. List pricing:
- Growth+: $1,250/org/month (includes lead nurturing and scoring)
- Plus+: $2,750/org/month (includes AI-powered scoring)
- Advanced+: $4,400/org/month
- Premium+: $15,000/org/month
https://www.salesforce.com/marketing/b2b-automation/pricing/
Marketo / Eloqua / Demandbase (enterprise reality)
Marketo, Eloqua, and ABM suites like Demandbase are powerful, and they're priced like it. In practice, teams usually land in the $30k-$100k+/year range depending on database size, modules, and support. If you don't have volume and governance, you'll pay enterprise money to recreate a messy spreadsheet at scale.
Don't ignore the plumbing: ad lead forms and iPaaS sync
If you run Facebook/Google/LinkedIn lead forms, your scoring system lives or dies on speed and attribution:
- Sync lead forms to CRM/MAP instantly (minutes, not hours).
- Stamp
lead_source,campaign, andcreated_atconsistently. - Trigger SLA timers off create time, not "first workflow run."
- Deduplicate on email + domain before routing, or you'll route the same person twice and destroy rep trust.
This is unglamorous work. It's also where a lot of "scoring doesn't work" stories start.
FAQ
What's the difference between a lead scoring model and a lead scoring system?
A lead scoring model is the logic (rules or ML) that assigns points or probabilities. A lead scoring system includes inputs, identity resolution, enrichment, routing, SLAs, reporting, feedback, and retraining, so the score changes what reps do, not just what a field says.
What's a good MQL score threshold in B2B?
A good B2B MQL threshold is typically 60-100 points in a rules-based setup. Start at 70, keep 4-6 bands (not one cutoff), and adjust after 2-4 weeks using sales acceptance rate plus SQL/opportunity conversion by band.
How do you prove a lead scoring system is working?
A scoring system's working when top bands show clear lift, usually 2-5x higher SQL or opportunity rates than the overall average, and when speed-to-lead improves (minutes/hours, not days). Validate with conversion-by-band tables, lift charts, and a 60-180 day backtest; for predictive, track ROC AUC and run champion/challenger.
Should you use AI/predictive lead scoring or rules-based scoring first?
Start rules-based first because it's explainable and you can iterate in days, not quarters. Move to predictive once you've got consistent outcomes and enough history, roughly 1,000+ leads and 100+ conversions, so the model learns real patterns instead of "who filled out a form."
How do you keep lead scoring accurate when your CRM data is incomplete?
Your fit score needs accurate titles, company size, industry, and tech stack. Prospeo's enrichment API returns 50+ data points per contact at a 92% match rate - filling the exact fields your scoring model depends on. At $0.01 per email, enrichment doesn't break your budget.
Fill every fit-score field automatically. No manual research, no guessing.
Summary: make lead scoring systems operational, not theoretical
The scoring math's the easy part. The hard (and valuable) part is turning lead scoring systems into a shared operating agreement: fit + engagement, clear bands, routing and SLAs, anti-signal rules, and validation that ties bands to SQLs and pipeline.
Do that, keep your inputs clean with verification and enrichment, and the score finally earns sales trust.
