Account Scoring in 2026: The Operator's Guide (Model -> Tiers -> Plays)
Finding someone's email and getting them to click a webinar link is easy. Getting the right buying committee at the right company to move in the same quarter is the hard part.
That's why SDR queues fill with students and competitors while AEs ignore "hot" leads.
Account scoring fixes this by prioritizing companies (not contacts) using fit, intent, and engagement. Build it like an ops system, not a math project.
What practitioners complain about (and they're right):
- Teams cram in 12+ signals, nobody trusts the score, and it dies in a dashboard.
- Intent data is noisy unless you gate it hard.
- One junior "researcher" can hijack engagement and waste a week of outbound.
What you need (quick version)
Use this checklist to build a model that gets used:
- Pick one outcome. Default: "Which accounts deserve human outbound this week?" Don't try to "predict revenue" on v1.
- Keep it to 4-6 signals. More signals creates a black box and kills rep trust.
- Use fit + intent + engagement. Fit = ICP match. Intent = in-market research. Engagement = real interactions with you.
- Add 2-3 disqualifiers. Hard "no's" prevent false urgency and rep resentment.
- Score accounts, not people. Committees buy; individuals browse.
- Bucket into tiers. Reps act on Platinum/Gold/Silver/Bronze faster than "73 vs 77."
- Ship a one-line "why." Every score needs an explanation a rep can repeat in a standup.
- Decide routing + SLA before launch. If a Platinum account doesn't create an owner and a clock, you built a report, not a system.
Why account scoring exists (and why lead scoring breaks in B2B)
Lead scoring was built for a simpler world: one person fills out a form, marketing nurtures, sales calls, deal closes. In modern B2B, that's fantasy.
A typical purchase involves 13 stakeholders, and even "just the decision makers" is still 6-10 people. TractionComplete's summary of Forrester/Gartner puts it in that range. That's the core reason account scoring exists: value and intent live at the account level, not in one contact record.
Lead scoring fails in two predictable ways:
- The "junior researcher" trap. A student, intern, or junior analyst binge-reads content and racks up engagement points. Your system screams "hot lead," and sales burns cycles.
- The "silent committee" problem. A perfect-fit account has multiple senior stakeholders sniffing around - ads, forwarded emails, internal meetings - but no single person crosses your MQL threshold.
Here's the uncomfortable truth: engagement scoring measures curiosity unless you force it to measure ability to buy. I've watched teams build elaborate HubSpot scoring models only to discover their biggest deal came from a "12/100" contact who booked a demo cold, while the "95/100" leads were doing research for a class.
Mini callout: If your scoring model can't separate "interested" from "able to buy," it's not scoring. It's content analytics.

Lead vs account vs opportunity scoring (use the right one)
The fastest way to break this is to use it for the wrong job. You've got three scoring types that look similar in a dashboard and behave completely differently in production.

Scoring taxonomy (and what each is for)
| Scoring type | Unit | Best for | When it breaks |
|---|---|---|---|
| Lead scoring | Person | High-volume inbound | Committees, ABM |
| Account scoring | Company | ABM + outbound focus | Bad matching/rollups |
| Opportunity scoring | Deal | Forecast + deal priority | Weak CRM hygiene |
Lead scoring ranks people. Account scoring ranks organizations by rolling up people and signals. Opportunity scoring ranks open deals to focus pipeline review and forecasting.
Build-first decision rules (the heuristics that save you months)
Use these defaults:
- If you sell lower-ticket deals (roughly under $25K/year), with 1-3 decision makers, and lots of inbound volume: build lead scoring first.
- If you sell bigger deals (roughly over $50K/year), with 5+ stakeholders, and you run ABM or enterprise outbound: build account scoring first.
Opportunity scoring comes last. Don't build it until your CRM is disciplined, because opportunity scoring trains on opportunity fields, and those fields are where hygiene goes to die.
A practical opportunity score uses factors like:
- Deal size / expansion potential
- Stage velocity
- Competition risk
- Similarity history (segment/vertical/stack)
- Buying signals inside the deal (security review, legal redlines, exec sponsor)
Operator rule: if reps can't keep stages, close dates, and next steps current, opportunity scoring becomes a fancy way to prioritize fiction.
Your fit-intent-engagement model collapses when firmographics are stale and emails bounce. Prospeo's 300M+ profiles refresh every 7 days - not 6 weeks - with 30+ filters for industry, tech stack, headcount growth, department size, and funding stage. That's your entire fit layer, scored and verified, at $0.01/email.
Feed your account scoring model data that's actually current.
The only model most teams need: Fit + Intent + Engagement
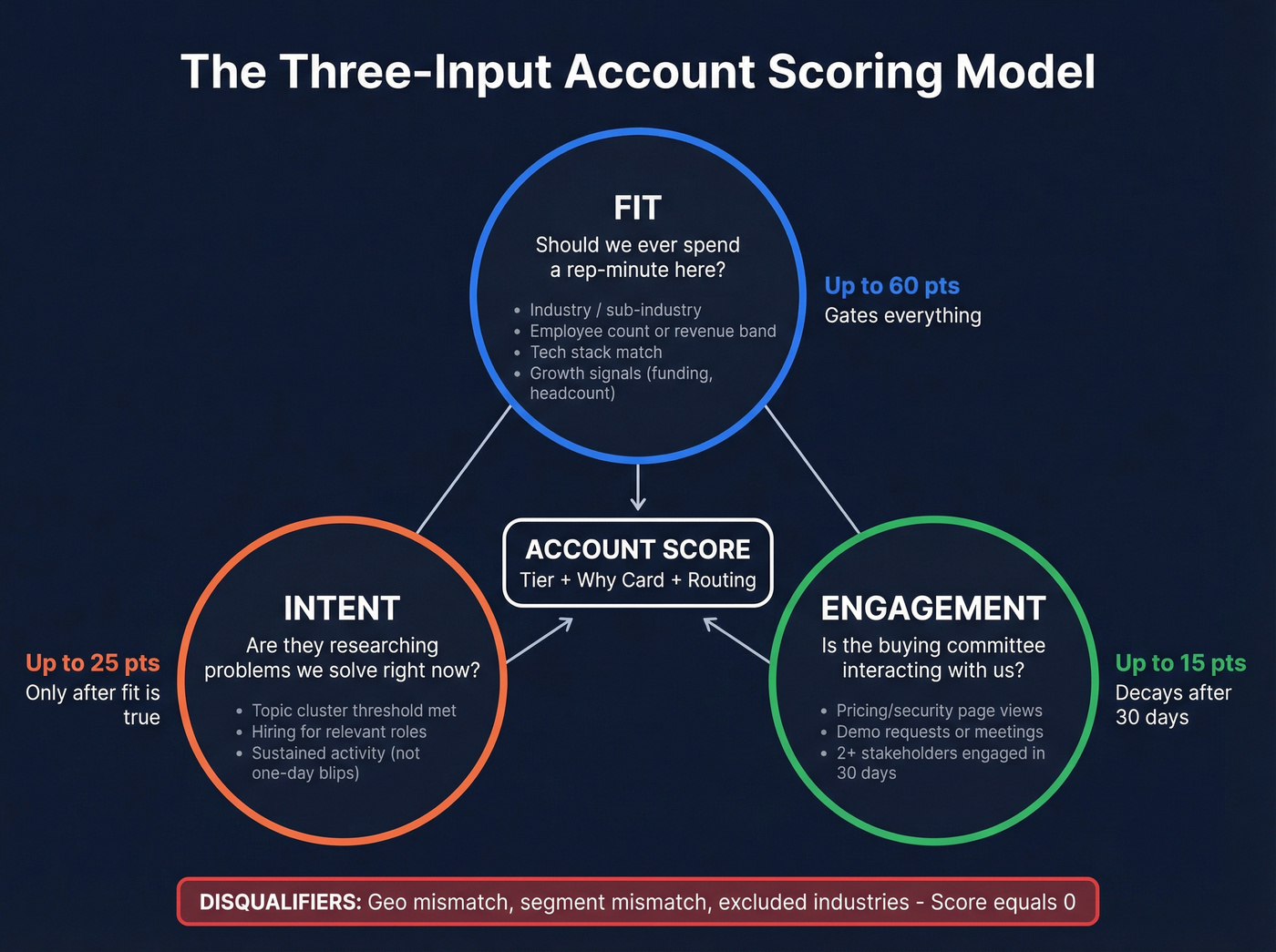
Most scoring frameworks are over-engineered. The one that survives contact with reality is the three-input model: fit + intent + engagement.
It's simple on purpose.
Fit (ICP match)
Fit answers: "Should we ever spend a rep-minute here?"
Use strict fit signals:
- Industry / sub-industry
- Employee count or revenue band
- Geography
- Tech stack (or "uses competitor X")
- Growth signals (headcount growth, funding stage)
- Department size (e.g., 20+ engineers)
Rule: fit gates everything. If the account isn't in your ICP, don't let intent or engagement rescue it.
A useful way to operationalize fit is an account fit score (firmographics + tech + exclusions) that you compute once and refresh when firmographics change.
Intent (in-market signals)
Intent answers: "Are they researching problems we solve right now?"
Intent is powerful and noisy. Treat it like a smoke alarm: useful when it's calibrated, unbearable when it's not.
Make intent usable with:
- Topic gating: only count intent on 10-30 topics that map to core use cases
- Thresholds: require multiple hits or sustained activity (not a one-day blip)
- Fit gate first: intent only matters after fit is true
Engagement (first-party interaction)
Engagement answers: "Is the buying committee interacting with us?"
Count account-level engagement:
- High-intent page views (pricing, integrations, security)
- Demo requests / contact sales
- Replies to outbound
- Meetings booked
- Product usage (for PLG motions)
Engagement is easy to measure and easy to misread. Fix that with role modifiers and disqualifiers.
Use/skip guidance (so you don't overbuild)
Use this model when you sell to committees and need a weekly "work this list" view.
Skip fancy scoring until you've got clean account matching in your CRM, reliable role/title identification, and engagement tracking tied to downstream outcomes (meetings/opps). If those aren't true, you'll spend your time arguing about weights instead of fixing the plumbing.
If you want a baseline reference, Demandbase's framing is a clean starting point: Demandbase's account scoring model.
How to build an account scoring model (rules-based, fast, explainable)
Rules-based scoring wins first because it's explainable. Predictive comes later.
Your v1 goal isn't a perfect 0-100. Your v1 goal is a believable top tier and a believable "do not touch" tier.
Pick 4-6 signals + 2-3 disqualifiers
Start with 4-6 signals max.
A practical starter set:
Fit (choose 2-3)
- Target industry
- Company size band
- Tech stack match
- Growth signal (headcount growth, funding stage)
Intent (choose 1-2)
- Intent topic cluster threshold met
- Hiring for relevant roles
Engagement (choose 1-2)
- Multiple stakeholders engaged in last 30 days
- High-intent page views
- Replies/meetings booked
Add 2-3 disqualifiers (hard stops):
- Geography mismatch
- Segment mismatch (too small / too large)
- Excluded industries
- Existing customer (for acquisition) or churn-risk (for expansion)
Disqualifiers should either set the score to 0 or cap the tier.
Set weights without chasing a perfect 0-100
Hot take: build tiers first, weights second. If you obsess over whether intent is worth 18 points or 22 points, you'll waste weeks and still be wrong.
A simple rubric that works:
- Fit: up to 60 points
- Intent: up to 25 points
- Engagement: up to 15 points
Example weights:
| Signal | Points |
|---|---|
| Target industry | +20 |
| Size in band | +20 |
| Tech stack match | +20 |
| Intent topic threshold met | +15 |
| Hiring signal | +10 |
| 2+ stakeholders engaged | +15 |
| Disqualifier hit | Score = 0 |
Add recency weighting (simple decay defaults)
If you don't decay signals, your model becomes a museum.

Use this default:
- Engagement window: 30 days
- Intent window: 45-60 days
- Fit: no decay
Implementation:
- Engagement 0-30 days: 100% points
- 31-60: 50%
- 61-90: 25%
90: 0%
Create a "Why this score" card
Adoption lives or dies on explainability.

Every scored account gets a one-line "why," written back to the CRM:
"Platinum because: ICP fit (Fintech, 500-1,000 emp) + uses Snowflake + 3 stakeholders engaged in last 14 days + intent spike on 'data enrichment'."
Real talk: the "why" is often more valuable than the number.
Make it real in your CRM: contact -> account rollups, modifiers, refresh
A scoring model in a spreadsheet is a hobby. A scoring model in your CRM is a revenue system.
The mechanics:
- Capture contact signals (engagement + role)
- Roll up to the account
- Apply modifiers so the wrong people don't dominate
- Refresh on a cadence that matches your motion
LeanData's guide is a clear reference for matching + rollups: LeanData's matching + account scoring guide.
A practical implementation pattern (fields, objects, automation)
Here's the pattern that works in Salesforce or HubSpot without turning your CRM into a science fair:
- Contact/Lead fields:
Engagement_Points_30d,Role_Modifier,Last_High_Intent_Engagement_Date - Account fields:
Fit_Score,Intent_Score_60d,Engagement_Score_30d,Account_Score_Total,Tier,Score_Why,MQA_Date - Automation (daily):
- recompute decayed engagement/intent points
- roll up contact signals to account
- set tier thresholds
- write/update the
Score_Whystring - trigger routing + SLA tasks when an account crosses into Platinum/Gold
If your scoring doesn't write back score + tier + why + timestamp, it won't survive handoffs.
Which rollup operator to use (sum vs max vs median)
Rollups sound simple until they lie to you.

| Operator | When it's correct | When it lies |
|---|---|---|
| Sum | Many signals matter | Inflates big accounts |
| Max | One strong signal is enough | One noisy contact wins |
| Median | You want "typical" | Hides key stakeholders |
| Min | You need weakest-link | Too conservative |
Defaults:
- Engagement rollup: max (or sum) with role modifiers (senior activity should dominate)
- Stakeholder count: sum
- Fit: account-native (don't roll up)
Title/role modifiers that prevent "student researcher" false positives
Fix the classic failure mode: one junior person spikes engagement and drags the whole account into "hot."
Do this:
- Zero out interns, students, consultants, test titles
- Apply multipliers:
- Target buyer roles (Sales Ops / RevOps): 10x
- Head/Director/VP: 20x
Authority dominates curiosity. Every time.
Refresh cadence + score windows
Default to daily refresh. Weekly refresh means you work last week's news.
- Daily refresh for outbound sequences, paid ads, SDR queues
- Weekly refresh only for slow motions with low engagement volume
Turn scoring into revenue: tiers, routing, SLAs, and plays
A score that doesn't change behavior is just a number.
Your system must output:
- Tier (level of effort)
- Owner (who works it)
- Clock (when it must be acted on)
Tiering schema (A/B/C or Platinum/Gold/Silver/Bronze)
Two tiering patterns work:
- A/B/C (simple, internal)
- Platinum/Gold/Silver/Bronze (clear for automations)
A common ABM pattern: Tier 1 = 50-100 accounts. That's the named set where deep research and personalization pays off.
Steal this Tier + SLA table:
| Tier | Typical volume | SLA | Primary motion |
|---|---|---|---|
| Platinum | 50-100 | 24 hrs | 1:1 outbound |
| Gold | 200-500 | 48 hrs | 1:few plays |
| Silver | 1k-5k | 5 biz days | light outbound |
| Bronze | rest | none | inbound only |
Routing rules + SLAs (who does what by when)
Define handoffs in plain language:
- MQA: account meets score threshold and enters a tier
- SAL: sales accepts and commits to action
- SQL/SQO: sales-qualified opportunity (your org's definition)
Routing rules that work:
- Platinum -> named AE + SDR pair, immediate task creation
- Gold -> SDR queue by territory/segment
- Silver -> automated nurture + weekly re-check
- Bronze -> suppress outbound unless inbound intent spikes
Fairness rules (so the score doesn't create rep resentment)
High-scoring accounts are a scarce resource. If you don't distribute them fairly, your team will quietly sabotage the system.
Use these mechanics:
- Capacity caps: each rep can hold X Platinum and Y Gold at a time; overflow goes back to the queue.
- Round-robin within tier: distribute Platinum/Gold evenly inside each segment/territory.
- Aging rules: if an account isn't touched within SLA, it re-routes (or escalates) automatically.
- Required "return reasons": when a rep returns an MQA, they must pick one:
- bad data / wrong account match
- no-fit (disqualifier missed)
- timing (not in market)
- already in active conversation
- duplicate / already owned
Those return reasons become your feedback loop. They tell you whether to fix data, disqualifiers, routing, or thresholds without guessing.
Plays by tier (ads, outbound, exec outreach, nurture, "do not touch")
Attach plays to tiers so the system runs itself:
- Platinum: exec-to-exec outreach, custom POV, direct mail, tight sequences, meeting goal
- Gold: semi-personal outbound, retargeting, webinar invites, partner plays
- Silver: lighter sequences, periodic check-ins, content mapped to intent topics
- Bronze: "do not touch" unless inbound (protect rep time and email reputation)
One pattern I like: Platinum/Gold gets an auto-generated "today list" for SDRs. Silver gets a "this month" list. Bronze gets nothing.
Data quality prerequisites (the part that decides if scoring works)
This fails in production for one boring reason: your inputs are wrong.
Poor data quality is expensive, duplicates inflate metrics, and B2B contact data decays fast. If your model is built on stale contacts and mismatched accounts, you'll route the right company to the wrong person and blame "scoring" - which is exactly how good ops projects die.
The fix order (do this, in this sequence)
Do this in order to avoid rework:
- Deduplicate accounts and contacts
- Standardize firmographics (industry, size, region)
- Verify emails + refresh contacts (so engagement attaches to the right person)
- Enrich missing fields (titles, department, tech signals)
- Then tune weights and thresholds
The fastest lever: accurate, fresh contact data (and why it changes scoring)
Here's the thing: scoring doesn't break because your weights are off by five points. It breaks because engagement attaches to the wrong contact, titles are missing so your role modifiers don't fire, and duplicates split signals across three "different" accounts.
In our experience, the quickest way to stabilize an account scoring system is to fix contact accuracy and refresh cadence first, then worry about fancy modeling.
Prospeo ("The B2B data platform built for accuracy") is built for exactly that layer of the stack: verified emails, verified mobile numbers, enrichment, and intent topics you can gate hard. It gives you 300M+ professional profiles, 143M+ verified emails, and 125M+ verified mobile numbers, refreshed every 7 days (the industry average is about 6 weeks), so your scoring inputs stop drifting between quarters.
If you want to see it in action, picture a common RevOps fire drill: an SDR books a meeting from a "Platinum" account, the AE shows up, and the prospect says, "I'm not the right person - I forwarded this to our VP last week." With verified contact data and reliable titles, that engagement rolls up to the right account, the VP gets weighted correctly, and your "why" card stops sounding like a guess.
Pricing is credit-based and transparent at ~$0.01 per verified email, with a free tier that includes 75 emails + 100 Chrome extension credits/month. No contracts. Cancel anytime.
Validate and govern the model (so reps trust it)
If you don't validate scoring, you're ranking accounts by vibes.
You don't need a data science team. You need three dashboards and a monthly habit.
Disciplined account-based motions win: opportunities from accounts receiving an account-based approach close at 53% vs 19% for demand gen. That lift comes from focus and follow-through, not magic, and it only shows up if your routing and SLAs are real (not "best effort").
Backtesting: lift by decile + precision@K
Two metrics tell you if your model separates signal from noise:
Lift by decile
- Sort accounts by score.
- Split into 10 deciles.
- Compute conversion rate per decile (MQA->Opp or MQA->Meeting).
Precision@K
- Pick K = the number of accounts your team can work (top 50/week).
- Precision@K = % of those accounts that hit the outcome within the window (e.g., opp created in 60 days).
If decile 1 doesn't crush decile 10, your inputs or gates are wrong. If lift looks fine but precision@K is weak, your routing/SLA execution is broken.
Adoption dashboards (the missing piece most teams ignore)
A model can be "accurate" and still fail because reps don't work it.
Track:
- % of Platinum accounts touched within SLA
- Touches per tier per week
- Meeting rate by tier
- MQA->SAL rate by rep/team
- Returned/disqualified reasons (bad data vs no-fit vs timing)
This is where you catch the real killers: ignored queues, overloaded reps, and broken routing.
Benchmarks (and what to do when none exist)
Benchmarks are messy because stage definitions vary. Still, you need guardrails.
Use these as working ranges, then replace them with your own baselines:
- Lead->MQL averages around 31% (First Page Sage, 2026), with B2B SaaS higher in many datasets.
- MQL->Opp efficiency target: 25%+ is a solid "we're not wasting sales time" bar.
For account-based models, use working ranges as guardrails while you build your own baselines:
- MQA->Opp overall: 10-30%
- Top decile MQA->Opp: 30-50%
If you're below range, don't touch weights first. Check SLA compliance, duplicates, and owner assignment.
When to go predictive (and when it hurts)
Rules-based wins until you've got clean history. Predictive scoring is worth it when you can train on consistent conversion events and operationalize daily updates.
Decision rules:
- No clean lifecycle stages and conversion events -> rules-based.
- Less than 6 months of usable history -> rules-based.
- Fewer than 10 conversions for the outcome -> rules-based.
- Can't write scores back to CRM daily -> rules-based.
Adobe's guidance is unusually specific: models run daily and output relative ranking, not a literal close probability, and they also output percentiles (1-100) to show where an account sits vs the rest. If you want predictive without a warehouse build, choose a system that writes scores to CRM daily and exposes the top drivers behind each score; if it can't explain itself, reps won't use it.
Drift checks + refresh discipline
Monthly checks:
- Score distribution shift (are too many accounts suddenly Platinum?)
- Missing data rate by key field (industry, size, tech)
- Duplicate rate (accounts and contacts)
- Conversion rate by tier (Platinum still outperforming?)
Quarterly checks:
- Revisit disqualifiers (new regions, new segments)
- Re-tune decay windows (sales cycle changes)
- Audit "why this score" explanations (do they still match reality?)
Templates + worked examples (acquisition and expansion)
Acquisition and expansion scoring are cousins, not twins. Acquisition answers "should we break in?" Expansion answers "where's the next dollar inside customers?"
Acquisition scoring example
Goal: prioritize net-new accounts for outbound this week.
Gates (must pass):
- Region = NA/EU
- Size = 200-2,000 employees
- Industry = target list
Score components (100 max):
| Category | Signal | Points |
|---|---|---|
| Fit (60) | Target industry | 20 |
| Size in band | 20 | |
| Tech stack match | 20 | |
| Intent (25) | Intent topics >= threshold | 15 |
| Hiring for key roles | 10 | |
| Engagement (15) | 2+ stakeholders engaged | 15 |
Tier thresholds:
- Platinum: 80-100
- Gold: 65-79
- Silver: 45-64
- Bronze: <45
"Why" card pattern:
- "Gold because: 700 emp + target industry + uses Snowflake + hiring RevOps + 1 director engaged last 21 days."
Worked example (full math)
- Acme Fintech is in a target industry: +20
- 900 employees (in band): +20
- Uses Snowflake (tech match): +20
- Intent threshold met on your gated topics: +15
- Hiring RevOps: +10
- 3 stakeholders engaged in last 14 days: +15
- Disqualifiers: none
Total = 100. Tier = Platinum.
That's exactly what you want: the model screams "work this now," and the "why" is obvious.
Operator note: if you're feeding sequences from Sales Navigator lists, this is where rollups matter. One engaged contact should never outrank an account with three director+ stakeholders showing intent.
Expansion scoring example
Goal: prioritize existing customers for upsell/cross-sell.
Expansion signals change because fit is already true. Now you care about footprint, access, and potential, and you also need to avoid the classic mistake of treating "busy CSM inbox" as "expansion intent" when it's really support noise.
Score components (100 max):
| Category | Signal | Points |
|---|---|---|
| Footprint (35) | Product usage breadth | 20 |
| New team adopting | 15 | |
| Access (25) | Decision-maker mapped | 15 |
| Exec sponsor engaged | 10 | |
| Potential (25) | Revenue potential band | 15 |
| Strategic importance | 10 | |
| Engagement (15) | QBR attended / replies | 15 |
Disqualifiers:
- Active churn risk -> cap at Silver
- Contract locked for 9+ months -> decay engagement impact
This is where "strategic importance" matters. A smaller account that's a logo in your target vertical can beat a bigger account that's off-strategy.
Operator wrap (do this before you touch weights)
If you do only three things this week:
- Define Platinum in plain English (fit + intent + engagement + disqualifiers).
- Ship tier + routing + SLA so the score creates action, not debate.
- Add the "why" card so reps trust the system on day one.
Everything else is tuning.
Intent signals are noise without accurate contact data to act on them. Prospeo combines Bombora intent data across 15,000 topics with 98% verified emails and 125M+ direct dials - so when an account hits Platinum tier, your reps reach the actual buying committee, not a dead inbox.
Turn scored accounts into booked meetings, not bounced emails.
Summary: make account scoring operational, not theoretical
Account scoring works when it's explainable (a short "why"), gated by fit, decayed by recency, and enforced with tiers, routing, and SLAs. Keep v1 rules-based, validate with lift-by-decile and precision@K, and fix data quality first, because clean matching and fresh contacts decide whether your score drives pipeline or just creates arguments.
FAQ
What's the difference between account scoring and lead scoring?
Account scoring ranks companies using aggregated fit, intent, and engagement across stakeholders. Lead scoring ranks individual people by profile and activity. If you sell to committees, account scoring is the default, and it pairs well with lead scoring when you need both volume triage and ABM focus.
How do you roll up contact engagement into an account score?
Roll up contact engagement with max (or sum) (to detect any senior activity) and sum (to count engaged stakeholders), then apply role modifiers so authority outweighs curiosity. Write the result back as score + tier + a one-line "why."
What benchmarks should you use for account scoring?
Use internal baselines first, but start with working ranges: MQA->Opp overall 10-30% and top decile 30-50%. If you're below range, fix SLA compliance, duplicates, and routing before you touch weights.
What data do you need for account scoring, and how can Prospeo help?
You need clean account matching, deduped contacts, reliable firmographics, verified emails, and enrichment for missing fields like titles. Prospeo provides 98% verified email accuracy, a 7-day refresh cycle, 83% enrichment match rate, 92% API match rate, and 15,000 intent topics (powered by Bombora) to keep your score trustworthy.